dave spink toolset
|
|
dave spink toolset |
|
|
DEEP LEARNING BENCHMARK SUITE (DLBS): |
|||
| OVERVIEW | JSON FILE | NVIDIA | TENSORFLOW |
| CAFFE2 | INFERENCE | ||
THE PROJECTVerizon (VMG) asked us for help in implementing a GPU benchmarking suite for testing different frameworks e.g. tensorflow, PyTorch, Caffe2 etc. Hence, we implemented the HPE DLBS created by Sergey and Natalia. OVERVIEWThe DBLS is for designed for running consistent and reproducible AI/ML benchmark experiments. It's licensed under Apache 2.0. Supports:
Installation Overview:
Frameworks:
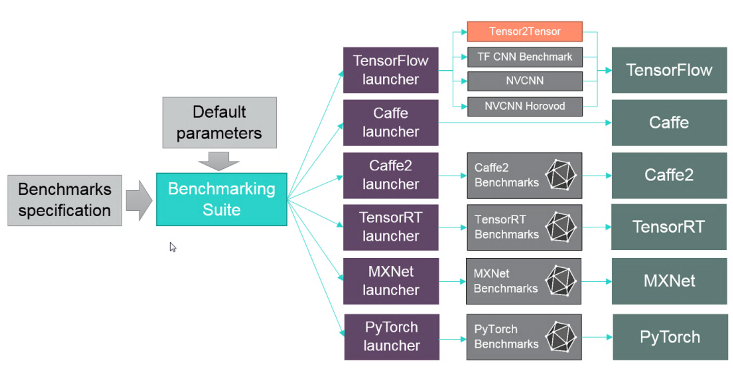
Architecture Overview:
DLBS is the experimenter (benchmarking suite) while the benchmarks run in containers. You start with frameworks on the right and we use benchmarks (framework specific) to train neural networks. Training benchmark:
Synthetic data vs. Real Data for benchmarking:
Inference
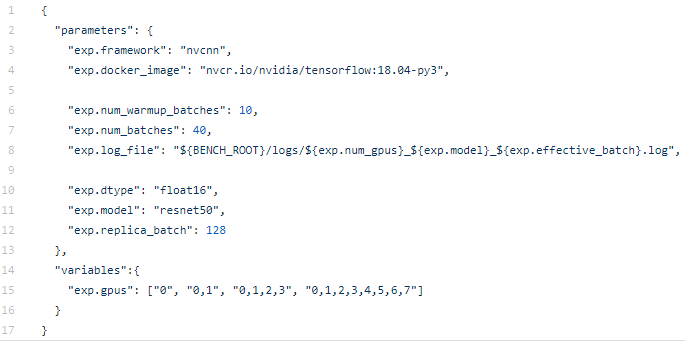
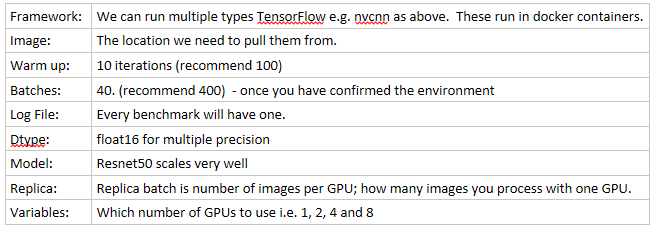
JSON FILEConfiguration Run JSON File: $ cd .tutorials/recipes/multi_gpu_compute_scaling $ cat config.json
Results:
{
"exp.device_type": "gpu",
"exp.framework_title": "TensorFlow-nvcnn",
"exp.framework_ver": "1.7.0",
"exp.model_title": "ResNet50",
"exp.phase": "training",
"exp.replica_batch": 128,
"results.throughput": 2349.2708413786054,
"results.time": 217.93996289484733
}
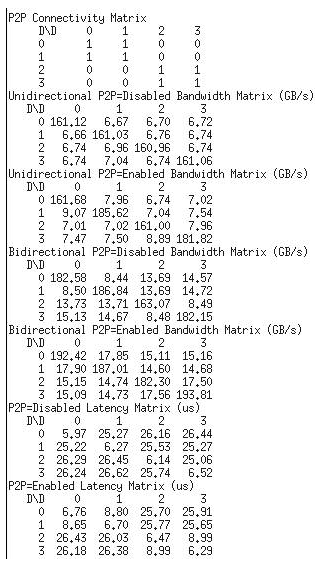
Results Time - Is an average time in milliseconds to process one batch of data. Results Throughput - Is the number of instances per second, in this case, number of images/seconds. NVIDIACheck NVIDIA drivers: # nvidia-smi !!check the driver version is NVIDIA Driver: 396.26 or later. (410.48) Check for GPU-to-GPU communication (bandwidthTest): # Check CUDA installation. You should be able to see cuda-install-samples-9.0.sh file or similar depending on CUDA version. ls /usr/local/cuda/bin # Get sample projects into home folder /usr/local/cuda/bin/cuda-install-samples-* $HOME # Build projects cd $HOME/NVIDIA_CUDA-*/1_Utilities/p2pBandwidthLatencyTest make # Run it ./p2pBandwidthLatencyTest # If you see output similar to this one, everything's fine.
Install Docker: See Docker for installation instructions. NVIDIA Docker Package: $ wget -P /tmp https://github.com/NVIDIA/nvidia-docker/releases/download/v1.0.1/nvidia-docker-1.0.1-1.x86_64.rpm $ sudo rpm -i /tmp/nvidia-docker*.rpm && rm /tmp/nvidia-docker*.rpm $ sudo systemctl start nvidia-docker TENSORFLOWClone DLBS: $ cd !!home directory $ git clone https://github.com/HewlettPackard/dlcookbook-dlbs dlbs Cloning into 'dlbs'... Setup environment paths: $ cd dlbs $ export BENCH_ROOT=`pwd` $ ls -l scripts/environment.sh **check executable $ . ./scripts/environment.sh $ echo $PYTHONPATH $reporter Pull images, login to https://ngc.nvidia.com $ docker login nvcr.io Username: $oauthtoken Password: Verify you can run docker and/or nvidia-docker: $ docker run -ti nvcr.io/nvidia/tensorflow:18.07-py3 /bin/bash $ nvidia-docker run -ti nvcr.io/nvidia/tensorflow:18.07-py3 /bin/bash $ nvidia-docker run -ti nvcr.io/nvidia/tensorflow:18.07-py3 nvidia-smi !!Check you see GPUs inside the docker container. See a list of frameworks:
$ python ./python/dlbs/experimenter.py help --frameworks --no-colors
TensorFlow
nvtfcnn Highly optimized benchmark backend that provides best results on multi-GPU machines.
This backend must be used for best performance.
NGC container: nvcr.io/nvidia/tensorflow:18.07-py3
nvcnn Previous version of the 'nvtfcnn' benchmark backend.
NGC container: nvcr.io/nvidia/tensorflow:18.04-py3
tensorflow Google's TF_CNN_BENCHMARKS project. Will not provide very good performance with 8 GPUs.
Reference DLBS container: hpe/tensorflow:cuda9-cudnn7
Caffe
bvlc_caffe Benchmarks based on original BVLC Caffe implementation.
Reference DLBS container: hpe/bvlc_caffe:cuda9-cudnn7
nvidia_caffe Benchmarks based on NVIDIA's version of BVLC Caffe.
NGC container: nvcr.io/nvidia/caffe:18.05-py2
intel_caffe Intel's version of BVLC Caffe suitable for CPUs.
Reference DLBS container: hpe/intel_caffe:cuda9-cudnn7
Caffes
caffe2 Default benchmark backend for Caffe2 framework.
NGC container: nvcr.io/nvidia/caffe2:18.05-py2
MXNET
mxnet Default benchmark backend for MXNET framework.
NGC container: nvcr.io/nvidia/mxnet:18.05-py2
PyTorch
pytorch Default benchmark backend for PyTorch framework.'
NGC container: nvcr.io/nvidia/pytorch:18.06-py3
TensorRT
tensorrt Default benchmark backend for TensorRT inference engine.
DLBS container: dlbs/tensorrt:18.10
Create JSON file:
$ vi test.json
{
"parameters": {
"exp.framework": "nvcnn",
"exp.docker_image": "nvcr.io/nvidia/tensorflow:18.07-py3",
"exp.num_warmup_batches": 10,
"exp.num_batches": 40,
"exp.log_file": "./logs/${exp.num_gpus}_${exp.model}_${exp.effective_batch}.log",
"exp.dtype": "float16",
"exp.model": "resnet50",
"exp.replica_batch": 128
},
"variables":{
"exp.gpus": ["0", "0,1", "0,1,2,3", "0,1,2,3,4,5,6,7"]
}
}
Run experiment: $ cd dlbs $ mkdir logs $ python ./python/dlbs/experimenter.py run --config test.json Create folder for benchmark results and parse log files:
$ mkdir $BENCH_ROOT/reports
$ params="exp.effective_batch,exp.replica_batch,results.time,results.throughput,exp.model_title,exp.phase,exp.gpus,exp.num_gpus,exp.model"
$ python $logparser ./logs/ --recursive --output_params ${params} --output_file ./reports/results.json
$ cat ./reports/results.json !! example for reference
"data": [
{
"exp.model_title": "ResNet50",
"exp.effective_batch": 128,
"exp.gpus": "0",
"results.time": 175.11470166412064,
"exp.phase": "training",
"exp.model": "resnet50",
"exp.replica_batch": 128,
"results.throughput": 730.949479304775,
"exp.num_gpus": 1
},
{
"exp.model_title": "ResNet50",
"exp.effective_batch": 256,
"exp.gpus": "0,1",
"results.time": 195.7543116174103,
"exp.phase": "training",
"exp.model": "resnet50",
"exp.replica_batch": 128,
"results.throughput": 1307.7617442232188,
"exp.num_gpus": 2
},
{
"exp.model_title": "ResNet50",
"exp.effective_batch": 512,
"exp.gpus": "0,1,2,3",
"results.time": 206.3526550066783,
"exp.phase": "training",
"exp.model": "resnet50",
"exp.replica_batch": 128,
"results.throughput": 2481.1893017971097,
"exp.num_gpus": 4
},
{
"exp.model_title": "ResNet50",
"exp.effective_batch": 1024,
"exp.gpus": "0,1,2,3,4,5,6,7",
"results.time": 229.79593794386074,
"exp.phase": "training",
"exp.model": "resnet50",
"exp.replica_batch": 128,
"results.throughput": 4456.127506701897,
"exp.num_gpus": 8
}
]
Create textual report: $ python $reporter --summary_file ./reports/results.json --type 'weak-scaling' --target_variable 'results.time' > ./reports/results.txt $ cat ./reports/results.txt Batch time (milliseconds) Network Batch 1 2 4 8 ResNet50 128 175.11 195.75 206.35 229.80 Inferences Per Second (IPS, throughput) Network Batch 1 2 4 8 ResNet50 128 730 1307 2481 4456 Speedup (instances per second) Network Batch 1 2 4 8 ResNet50 128 1 1.79 3.40 6.10 Efficiency = 100% * t1 / tN Network Batch 1 2 4 8 ResNet50 128 100.00 89.45 84.86 76.20 Other Training JSON files 01. fast:
{
"parameters": {
"pytorch.docker_image": "nvcr.io/nvidia/pytorch:18.06-py3",
"nvtfcnn.docker_image": "nvcr.io/nvidia/tensorflow:18.07-py3",
"exp.docker": true,
"exp.git_hashtag": "92ef23344c4bfd0e222677c4674fe4f24d154658",
"exp.num_warmup_batches": 100,
"exp.num_batches": 400,
"exp.log_file": "${BENCH_ROOT}/logs/${exp.framework}/${exp.data}/${exp.dtype}/$(\"${exp.gpus}\".replace(\",\",\".\"))$_${exp.model}_${exp.effective_batch}.log",
"exp.phase": "training",
"exp.sys_info": "cpuinfo,meminfo,lscpu,nvidiasmi,dmi"
},
"variables":{
"exp.framework": ["pytorch", "nvtfcnn"],
"exp.dtype": ["float16"],
"exp.gpus": ["0", "0,1", "0,1,2,3", "0,1,2,3,4,5,6,7"],
"exp.model": ["resnet50"],
"exp.replica_batch": [256]
}
}
Other Training JSON files 02. medium:
{
"parameters": {
"pytorch.docker_image": "nvcr.io/nvidia/pytorch:18.06-py3",
"nvtfcnn.docker_image": "nvcr.io/nvidia/tensorflow:18.07-py3",
"exp.docker": true,
"exp.git_hashtag": "92ef23344c4bfd0e222677c4674fe4f24d154658",
"exp.num_warmup_batches": 100,
"exp.num_batches": 400,
"exp.log_file": "${BENCH_ROOT}/logs/${exp.framework}/${exp.data}/${exp.dtype}/$(\"${exp.gpus}\".replace(\",\",\".\"))$_${exp.model}_${exp.effective_batch}.log",
"exp.phase": "training",
"exp.status": "disabled",
"exp.sys_info": "cpuinfo,meminfo,lscpu,nvidiasmi,dmi"
},
"variables":{
"exp.framework": ["pytorch", "nvtfcnn"],
"exp.dtype": ["float16"],
"exp.gpus": ["0", "0,1", "0,1,2,3", "0,1,2,3,4,5,6,7"],
"exp.model": ["resnet50", "alexnet_owt"],
"exp.replica_batch": [256, 1024]
},
"extensions": [
{"condition": {"exp.model":["alexnet_owt"], "exp.replica_batch":[1024]}, "parameters": {"exp.status": ""}},
{"condition": {"exp.model":["resnet50"], "exp.replica_batch":[256]}, "parameters": {"exp.status": ""}}
]
}
Other Training JSON files 03. complete:
{
"parameters": {
"pytorch.docker_image": "nvcr.io/nvidia/pytorch:18.06-py3",
"nvtfcnn.docker_image": "nvcr.io/nvidia/tensorflow:18.07-py3",
"exp.docker": true,
"exp.git_hashtag": "92ef23344c4bfd0e222677c4674fe4f24d154658",
"exp.num_warmup_batches": 100,
"exp.num_batches": 400,
"exp.log_file": "${BENCH_ROOT}/logs/${exp.framework}/${exp.data}/${exp.dtype}/$(\"${exp.gpus}\".replace(\",\",\".\"))$_${exp.model}_${exp.effective_batch}.log",
"exp.phase": "training",
"exp.status": "disabled",
"exp.sys_info": "cpuinfo,meminfo,lscpu,nvidiasmi,dmi"
},
"variables":{
"exp.framework": ["pytorch", "nvtfcnn"],
"exp.dtype": ["float16", "float32"],
"exp.gpus": ["0", "0,1", "0,1,2,3", "0,1,2,3,4,5,6,7"],
"exp.model": ["resnet50", "resnet152", "googlenet", "vgg16", "alexnet_owt"],
"exp.replica_batch": [64, 128, 256, 1024]
},
"extensions": [
{"condition": {"exp.model":"resnet50", "exp.dtype": "float16", "exp.replica_batch":[256]}, "parameters": {"exp.status": ""}},
{"condition": {"exp.model":"resnet50", "exp.dtype": "float32", "exp.replica_batch":[128]}, "parameters": {"exp.status": ""}},
{"condition": {"exp.model":"vgg16", "exp.dtype": "float16", "exp.replica_batch":[128]}, "parameters": {"exp.status": ""}},
{"condition": {"exp.model":"vgg16", "exp.dtype": "float32", "exp.replica_batch":[64]}, "parameters": {"exp.status": ""}},
{"condition": {"exp.model":["resnet152", "googlenet"], "exp.replica_batch":[128]}, "parameters": {"exp.status": ""}},
{"condition": {"exp.model":["alexnet_owt"], "exp.replica_batch":[1024]}, "parameters": {"exp.status": ""}}
]
}
$ docker pull nvcr.io/nvidia/caffe2:18.05-py2
CAFFE2Pull the optimized image from NVIDIA: $ docker pull nvcr.io/nvidia/caffe2:18.05-py2 Modify the JSON configuration file, see highlighted section below:
$ vi config.json
{
"parameters": {
"caffe2.docker_image": "nvcr.io/nvidia/caffe2:18.05-py2",
"exp.docker": true,
"exp.git_hashtag": "92ef23344c4bfd0e222677c4674fe4f24d154658",
"exp.num_warmup_batches": 100,
"exp.num_batches": 400,
"exp.log_file": "${BENCH_ROOT}/logs/${exp.framework}/${exp.data}/${exp.dtype}/$(\"${exp.gpus}\".replace(\",\",\".\"))$_${exp.model}_${exp.effective_batch}.log",
"exp.phase": "training",
"exp.sys_info": "cpuinfo,meminfo,lscpu,nvidiasmi,dmi"
},
"variables":{
"exp.framework": ["caffe2"],
"exp.dtype": ["float16"],
"exp.gpus": ["0", "0,1", "0,1,2,3", "0,1,2,3,4,5,6,7"],
"exp.model": ["resnet50"],
"exp.replica_batch": [256]
}
}
INFERENCELogin https://developer.nvidia.com/tensorrt and download nv-tensorrt-repo-ubuntu1604-cuda9.0-trt5.0.0.10-rc-20180906_1-1_amd64.deb
Build the framework: $ mv dlbs dlbs-bck1 $ git clone https://github.com/HewlettPackard/dlcookbook-dlbs dlbs $ mv nv-tensorrt-repo-ubuntu1604-cuda9.0-trt5.0.0.10-rc-20180906_1-1_amd64.deb ./dlbs/docker/tensorrt/18.11 $ cd dlbs/docker $ ./build.sh tensorrt/18.11 $ docker images $ cd $ cd ./yahoo/inference $ vi config.json **replace 18.10 with 18.11 Plan B (if the above build fails): Get docker binary image "dlbs_tensorrt:18.11" $ docker load --input dlbs_tensorrt:18.11 Inference JSON File
$ cat config.json
{
"parameters": {
"exp.num_warmup_batches": 100,
"exp.num_batches": 400,
"monitor.frequency": 0,
"exp.status": "disabled",
"exp.log_file": "${BENCH_ROOT}/${logdir}/$(\"${exp.gpus}\".replace(\",\",\".\"))$_${exp.model}_${exp.effective_batch}.log",
"exp.docker": true,
"exp.docker_image": "dlbs/tensorrt:18.11",
"exp.framework": "tensorrt",
"exp.phase": "inference",
"exp.dtype": "float16"
},
"variables": {
"exp.gpus": ["0", "0,4", "0,2,4,6", "0,1,2,3,4,5,6,7"],
"exp.model": ["alexnet_owt", "resnet152", "resnet50"],
"exp.replica_batch": [128, 256, 1024]
},
"extensions": [
{
"condition": {"exp.model": "alexnet_owt", "exp.replica_batch": [1024]},
"parameters": {"exp.status":"", "exp.num_batches": 500}
},
{
"condition": {"exp.model": "resnet152", "exp.replica_batch": [128]},
"parameters": {"exp.status":"", "exp.num_batches": 250}
},
{
"condition": {"exp.model": "resnet50", "exp.replica_batch": [256]},
"parameters": {"exp.status":"", "exp.num_batches": 300}
}
]
}
|